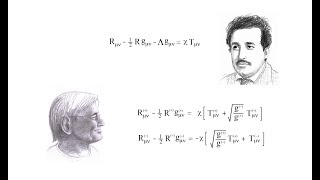Direct Preference Optimization (DPO) to finetune LLMs without reinforcement learning. DPO was one of the two Outstanding Main Track Runner-Up papers.
➡️ AI Coffee Break Merch! 🛍️ [ Ссылка ]
📜 Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. "Direct preference optimization: Your language model is secretly a reward model." arXiv preprint arXiv:2305.18290 (2023). [ Ссылка ]
Thanks to our Patrons who support us in Tier 2, 3, 4: 🙏
Dres. Trost GbR, Siltax, Vignesh Valliappan, @Mutual_Information , Kshitij
Outline:
00:00 DPO motivation
00:53 Finetuning with human feedback
01:39 RLHF explained
03:05 DPO explained
04:24 Why Reinforcement Learning in the first place?
05:58 Shortcomings
06:50 Results
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
🔥 Optionally, pay us a coffee to help with our Coffee Bean production! ☕
Patreon: [ Ссылка ]
Ko-fi: [ Ссылка ]
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
🔗 Links:
AICoffeeBreakQuiz: [ Ссылка ]
Twitter: [ Ссылка ]
Reddit: [ Ссылка ]
YouTube: [ Ссылка ]
#AICoffeeBreak #MsCoffeeBean #MachineLearning #AI #research
Video editing: Nils Trost
Music 🎵 : Ice & Fire - King Canyon

































































![Почему число 37 встречается повсюду? [Veritasium]](https://s2.save4k.ru/pic/26meYYVE2Yg/mqdefault.jpg)