Data Warehouse architectures are nowadays outdated or at least reach the limits of today's data requirements. Adding cheap, flexible cheap cloud storage towards a two-tier architecture made things more chaotic. Even though now machine learning requirements towards file-based data storage and unstructured data could be satisfied.
The Data Lakehouse is a new data concept leveraging the benefits of data warehouses like ACID, updates/merges/deletes and schema enforcement on a cheap and flexible cloud storage. In the past three years numerous leverage this concept successfully. Check it out :)
~~~~~~~~~~~~~ *Subscribe - Like - Comment - Challenge* ~~~~~~~~~~~~~
You want to master Data Engineering with PySpark? Subscribe here: [ Ссылка ]
Feel free to comment or challenge my explanations as always. Happy to learn also myself more by the community.
~~~~~~~~~~~~~~~~~~~~~~~ *Resources* ~~~~~~~~~~~~~~~~~~~~~~~
Link to Slides: [ Ссылка ]
~~~~~~~~~~~~~~~~~~~~~~~ *Chapters* ~~~~~~~~~~~~~~~~~~~~~~~
00:00 - Introduction
01:19 - What is the Lakehouse?
02:02 - Data Warehouses
04:06 - Two Tier Architecture
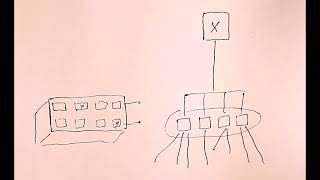
06:30 - Data Lakehouse Architecture
08:45 - Key Components of a Lakehouse
11:24 - Storage Frameworks as Meta Data Layer
13:03 - The Medallion Architecture
14:40 - Summary
#spark #pyspark #lakehouse #datalakehouse #deltalake #dataengineering #dataengineeringessentials